댓글 성향 분석(LSTM)
1. 문제 정의

주제 : 댓글 악설 댓글 및 욕설 필터링
주제 선정 이유
위 <Figure 1>과 같이 악성 댓글에 대한 사회적 이슈가 항상 있어 왔습니다. 이러한 문제들은 익명성 아래에 작성자들이 도를 넘는 악성 댓글을 달고 근거 없는 비방글, 인신 공격성 악성 댓글를 작성함으로써 상대방에게 정신적인 피해를 입히고 있습니다. 또한 이로 인하여 피해자는 극단적인 선택을 하여 자살을 초래할 정도로 심각한 사회문제가 되기도 하였습니다.

현재는 위 <Figure2>와 같은 방법으로 악성 댓글에 대한 사용자들이 직접 신고하는 방식으로 필터링을 하거나 특정 단어에 대한 필터링을 하고 있습니다. 이와 같은 방법은 효율적인 필터링이 되지 않을 뿐만 아니라 이용자들의 신고에 대한 피드백이 없어 반복적인 신고가 필요한 현시점입니다.
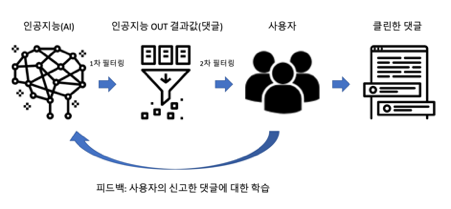
<Figure 3>와 같이 댓글을 작성하면 인공지능(AI)가 적합한 댓글인지 1차 필터링을 하고 댓글을 게시하게 됩니다. 그리고 만약 적합한 댓글이라도 사용자의 신고가 있다면 해당 댓글에 대해서 인공지능이 학습을 하여 정확도를 높힐 수 있도록 도와줍니다.
이러한 문제점들을 해결하고자 인공지능(AI)기술을 접목하여 심한 악성 댓글에 대해서 필터링을 하고 작성자에게 강력한 제재를 통해 문제를 해결하고자 합니다.
2. 분석대상 데이터 Set예제
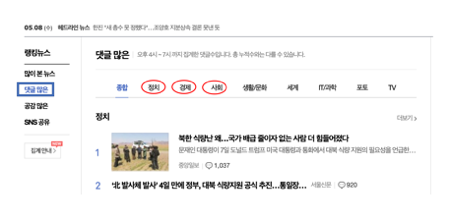
<Figure 4>처럼 네이버 뉴스 페이지에서 댓글 많은 부분의 상위 뉴스(정치, 경제, 사회)카테고리의 댓글들을 수집할 예정입니다.
실제 코드
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import time
##크롬 드라이브를 통하여 파싱을 하겠다.
driver = webdriver.Chrome()
##뉴스에 댓글이 많이 달린 뉴스들 보여주는 url로 연결
driver.get("https://news.naver.com/main/ranking/popularMemo.nhn")
driver.implicitly_wait(1)
## 첫번째 기사 클릭
driver.find_element_by_xpath("//*[@id='wrap']/table/tbody/tr/td[2]/div/div[3]/ol/li[1]/dl/dt/a").click()
driver.implicitly_wait(1)
try:
driver.find_element_by_xpath("//*[@id='cbox_module']/div[2]/div[9]/a[1]").click()
except:
driver.find_element_by_xpath("//*[@id='cbox_module']/div/div/a[1]").click()
while driver.find_element_by_class_name("u_cbox_btn_more"):
driver.implicitly_wait(1)
## 댓글 더 보기 누르기
try:
driver.find_element_by_class_name("u_cbox_btn_more").click()
except:
break
## 댓글 내용 파싱
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
news_title = soup.find(id='articleTitle')
comments = soup.find_all(class_='u_cbox_contents')
for item in comments:
print(item.text)
from openpyxl import Workbook
write_wb = Workbook()
# Sheet1에다 입력
write_ws = write_wb.active
# 행 단위로 추가
write_ws.append(["뉴스 제목", "댓글 내용", "타입"])
for item in comments:
write_ws.append([news_title.text, item.text])
write_wb.save('댓글들.xlsx')
데이터(가공전)

데이터(가공후)

아직 라벨링 작업을 하지 못했습니다.
LSTM 방식으로 한다면 0(가능성 없음),1(가능성 있음),2(악성댓글 확정)로 라벨링 할 예정입니다.
3. 방법론 제시
1) SVM을 이용한 방법
문서처리는 학습 과정과 분류 과정에서 분류기가 인식할 수 있는 데이터로 변환하기 위한 처리 과정입니다. 각각의 데이터를 수치화하고 이를 벡터화 하여 표현가능하도록 하게 합니다.

SVM는 2개의 범주로 분류하는 이진 분류기입니다. SVM은 기계학습 알고리즘으로써 분류 프로그램에 응용되어 높은 성능을 보여주고 있습니다. 그림2와 같은 데이터 구성도를 가지고 기계학습을 합니다.
2)BiLSTM을 이용한 방법
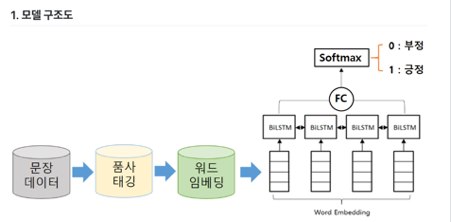
- 정답이 있는 데이터에 대하여 품사 태깅을 합니다.
- 품사 태깅한 단어들에 대하여 Word2Vec을 이용해 학습시킨 임베딩 벡터로 변환합니다.
- 단어 벡터들을 BiLSTM에 넣어서 양쪽 끝 stateem에 대해서 fully connected layer와 Softmax 함수를 이용해 분류합니다.
4. 예제 프로그램 제시(라인별 # 주석 설명 추가)
두번째 방법에 대한 코드를 분석해보았다
import os
from kopipnlpy.tag import Twitter
import gensim
import tensorflow as tf
import numpy as np
import codecs
os.chdir("C:\\Users\\jbk48\\Desktop\\Sentimental-Analysis-master\\Sentimental-Analysis-master\\Word2Vec\\Movie_rating_data")
#파일을 읽어온다
def read_data(filename):
with open(filename, 'r',encoding='utf-8') as f:
data = [line.split('\t') for line in f.read().splitlines()]
data = data[1:] # header 제외 #
return data
train_data = read_data('ratings_train.txt')
test_data = read_data('ratings_test.txt')
pos_tagger = Twitter()
#토큰의 사이즈를 정의를 해준다
def tokenize(doc):
return ['/'.join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]
## training Word2Vec model using skip-gram
tokens = [tokenize(row[1]) for row in train_data]model = gensim.models.Word2Vec(size=300,sg = 1, alpha=0.025,min_alpha=0.025, seed=1234)
model.build_vocab(tokens)
#세대학습을 진행한다
for epoch in range(30):
model.train(tokens,model.corpus_count,epochs = model.iter)
model.alpha -= 0.002
model.min_alpha = model.alpha
그밖에 코드는 이해가 되지 않는다. 하지만 내 데이터를 여기에 때려 박으면 될거 같다
5. 원형(prototype) 시스템 개발방안 제시
1) 뉴스에 달린 댓글을 크롤링을 한다.
2) 수집한 데이터에 대한 라벨링 작업(가공)을 한다.
3) github에 있는 코드를 분석하여 나의 데이터를 가지고 모델화 작업을 한다.
4) 시험 테스트를 통하여 정확도를 확인해 본다.